ACL2022图文多模态预训练Tutorial整理
2023-04-29 来源:飞速影视
资料源:ACL 2022 Tutorial - Vision-Language Pretraining: Current Trends and the Future (vlp-tutorial-acl2022.github.io)Vision-Language Pretraining: Current Trends and the Future
An ACL 2022 tutorial by Aishwarya Agrawal (DeepMind, University of Montreal, Mila), Damien Teney (Idiap Research Institute), and Aida Nematzadeh (DeepMind).
目标:本教程的目标是概述处理多模态问题所需的要素,特别是视觉和语言。我们还将讨论该领域的一些开放性问题和有前景的未来方向。
在过去几年中,人们对建立多模态(视觉语言)模型越来越感兴趣,该模型是在更大但噪声更大的数据集上预训练的,其中两种模态(例如图像和文本)松散地相互对应(例如,ViLBERT和CLIP)。
给定一项任务(如视觉问答),这些模型通常会在特定任务的监督数据集上进行微调。除了更大的预训练数据集,transformer架构,特别是应用于两种模式的self-attantion,是最近预训练模型在下游任务上的出色表现的原因。
这种方法之所以吸引人,有几个原因:首先,预训练数据集通常是从网络上自动管理的,提供了巨大的数据集,收集成本可以忽略不计。第二,我们可以训练大型模型一次,并将其用于各种任务。最后,这些预训练方法比以前的任务特定模型表现更好或相当。一个有趣的问题是,除了良好的任务性能之外,这些预先训练的模型是否学习了更善于捕捉两种模式之间对齐的表示。
在本教程中,我们将重点介绍最近的视觉语言预训练范例。我们的目标是在多模态预训练区域之前,首先提供图像-语言数据集、基准和建模创新的背景。接下来,我们将讨论用于视觉语言预训练的不同系列模型,强调它们的优缺点。最后,我们讨论了通过统计学习进行视觉语言预训练的局限性,以及对替代方法(如因果建模)的需求。
接下来,我将从3个部分展示:第1部分:视觉-语言预训练前的视野。(主要讲预训练之前的多模态任务和数据集)第2部分:视觉-语言预训练的现代视野。(主要讲预训练结构、数据、评测等)第3部分:超越统计学习。(可解释性)
第一部分:Vision-Language landscape before the Pretraining Era
公共的VL任务(Common VL tasks)
图像索引(Image Retrieval):High level similarity,Easy evaluation(recall@k)指代表达物体(Grounding Referring Expressions):空间位置(Spatial Localization),细粒度(Finer Grained grounding), Easy evaluation。图像描述(Image Captioning):语言生成(Language generation),不容易评估(Difficult automatic evaluation)视觉问答(Visual Question Answering):从图中获取特定信息,相对容易评估。视觉对话(Visual Dialog):额外的上下文建模,很难去评估自由形式的答案。
为什么要有视觉和语言多模态?直觉:人类是在多模态环境中学习的。应用:对视觉障碍人士对帮助。网上购物或整理图片。科学:视觉识别。视觉理解。视觉中的语言。组合推理。常识推理。
任务指定的数据集和模型(Task specific datasets and models)
常用的模型结构:
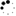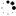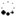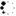
常用的数据集:
这里聊一下VQA:
Evaluation Code
为了与“人类精度”保持一致,机器精度在所有10组中取平均值。选择9组人类注释器。
多模态社区获得了什么?(What did the community gain?)
VQA的发展:性能的发展:VQAv2数据集,从2015年ICCV取得55的acc,到2021年取得近80的acc,提升了25%。模型的创新:基于网络的注意力(Grid based),基于区域的注意力(Region based),跨模态池化(Multimodal Pooling),组成网络(Compositional networks)。
开放问题和未来发展的途径(Open problems and avenues for future research)
Challenge1: 以视觉为基础的语言任务。Challenge2: 严格的评测指标。Ohter Challenges: 视觉实体计数,文字识别,组合推理,基于常识和知识的推理,处理真实世界的数据分布变化。未来的研究途径: 具有反事实的数据集,对话任务和数据集,基于视频的VL任务和数据集。
第二部分:Vision-Language Pretraining: Current Trends and the Future
为什么要多模态预训练?(Why Vision-Language Pretraining?)
基本的语言-视觉多模态预训练,是语言-视觉的基础。
一次训练,多次使用。多模态预训练模型,可以用于很多多模态任务和应用。
多模态预训练的目标:概述解决多模态问题(特别是视觉和语言)所需的要素。此外,讨论一些开放性问题。
预训练NLP模型的成功:NLP模型性能的提高是由于体系结构创新和更大的数据集。
多模态需要相似的预训练模型吗?数据集?模型?目标?
多模态预训练时如何开始的?
模型会使用相似的backbone,但是loss的设计,和预处理方面各有不同。
他们在一系列任务中,取得了Sota的成果。
典型的多模态Transformers(Joint Encoders结构)
对于语言特征,通常使用BERT模型的token作为输入,LM的loss。对于视觉,可以使用bounding box作为图片单词,作为输入。
是什么促使这些模型的成功?
是由于体系结构的进步还是大型预训练数据集?语言模型的损失是否足够好?模态之间的交叉对话(cross-attention)重要吗?什么是好的预训练数据集?
评估指标:Zero-shot 图片检索 Zero-shot图像检索直接评估预训练模型的优劣。
典型的损失函数:
语言/视觉模型:masked language/region modeling语言-视觉匹配:二分类任务或对比损失。
所有的损失函数我们都需要吗?[Hendricks et al. TACL, 2021]
使用正确的超参数,不需要图像建模loss。Vison-and-language or Vision-for-language?[Frank et al, 2021]
不同的注意力机制[Hendricks et al. TACL, 2021]
Merged attention 和 Coattention性能相似,且都明显好于Asymmetric attention。此外,模型结构很重要,仅有深度和参数量是不够的。
什么是好的预训练数据集?
预训练噪声越来越多,但是也越来越大了!
数据集需要注意的一个事项:语言
影响数据集好坏的原因:
1. 图片-文字索引:性能和图片并不相关,而是和文字的质量有关。
2. 图片-文字索引:更多的噪声会影响到模型的性能。
3. 图片-文字索引:合并数据集会带来更好的结果,但是采样方式很重要,建议加权采样更好的数据集。
4. 最佳的数据集,取决于任务。
因此:语言模型的损失是否足够好?不,我们需要更好的视觉模型损失。模态之间的交叉对话(cross-attention)重要吗?是的,跨模态注意力是很重要的。什么是好的预训练数据集?噪声水平和语言描述很重要!
模型结构
Dual Encoders(双流编码器结构)
用于图像和语言模态的两个独立编码器,两者之间没有串扰。[Weston et al. 2011; Frome et al., 2013; Kiros et al., 2014]检索任务非常成功[Chowdhury et al., 2018; Miech, Alayrac, et al.2020]
最近的大尺度双流编码器结构(Large-Scale Dual Encoders)
CLIP [Radford et al, 2021] and ALIGN [Jia et al, 2021]: Larger models & datasets其中ALIGN收集1.8B数据集,但是噪声比较多,使用了label smoothing。CLIP稍微清理了下数据集,拥有400M训练数据。需要在数据集的大小和噪声之间取得一个Tradeoff。[Jia et al, 2021]
编码器-解码器结构(Encoder-Decoders)
使用语言作为视觉或多模态的监督信号。需要的图片更少。
组合冻结模型(Combining Frozen (Pretrained) Models)
考虑到训练大型模型的成本,我们是否能够重用和组合现有的视觉或语言模型?但是,需要映射不同的特征空间->训练适配器层。Frozen, MAGMA, Flamingo
生成模型?(Moving Towards Generative Models)
统一图文多模态任务。有更好的在VQA中的泛化能力。如何正确的评估文本?
语言编码器(Language Encoder)
使用视觉信号作为语言的预训练。
不同方法的概述(Summary of Different Approaches)
为了构建强大的模型,我们需要首先更好的评估他们。
如何评估预训练模型?
使用特定下游任务任务头(ViLBERT, LXMERT, UNITER, OSCAR, VinVL)将所有下游任务视为无任务特定头的语言生成(VL-T5, VL-BART, SimVLM)。
如何使用特征?视觉任务(VirTex, CLIP, ALIGN),语言任务(Vokenization, M3P, VL-T%, SimVLM)
Zero-shot, few-shot
此外,对于文本-图像索引任务,可以从主题,动词,目标三个维度来进行粒度评估。
第三部分:Beyond statistical learning
让我们退后一步。。。
我们使用机器学习来建立模拟现实系统的预测模型。我们建立统计模型,利用相关性产生最佳预测,而不考虑与任务的相关性。
例如图像识别:模仿人类的标注。相关性预测:蓝色的背景/鸟。
视觉问题回答(VQA):模仿人类回答问题。预测会正确可能是错误的原因。训练数据是带有偏见的。预测相关性:问题类型/答案。
训练仅在训练分布内可靠。
模型使用的特征不一定与我们试图模拟的真实系统相同。
更多限制!统计模型只回答预测问题。
示例:如果一个模型,会根据工厂机器发出噪音来预测,该机器即将发生故障。
那么,该模型无法降低故障率。只能说明工厂隔音不起作用!
因为噪声不是导致机器故障的原因(噪声/故障指示一种相关性)。是凭常识显而易见的。
示例:预测在线新闻文章流行度(未来点击数)的NLP模型。
可解释性方法可能表明模型以来与标题长度。
但这并不意味着我们可以通过改变标题长度来改变受欢迎程度。不那么明显!
即使是简单的预测问题也应该显示:
对抗鲁棒性=>最坏情况下的OOD泛化。组合和跨任务概括=>重新利用所学知识的要素。分布变化的鲁棒性=>在训练中未看到的条件下的预测。
所有这些设置都违反了对统计学习至关重要的i.i.d.训练/测试数据的假设。
因果推理为理解如何克服这些限制提供了一个分析框架。
相关影视
训练日
2001/美国/剧情片突袭训练室
2022/大陆/大陆综艺怪兽训练营
2021/美国/动画片僵尸训练营
1988/台湾/剧情片宝贝训练营
2014/加拿大/爱情片青春训练班粤语版
2022/香港/香港剧乘风2023直播训练室
2023/大陆/大陆综艺青春训练班国语版
2022/香港/香港剧








合作伙伴
本站仅为学习交流之用,所有视频和图片均来自互联网收集而来,版权归原创者所有,本网站只提供web页面服务,并不提供资源存储,也不参与录制、上传
若本站收录的节目无意侵犯了贵司版权,请发邮件(我们会在3个工作日内删除侵权内容,谢谢。)
若本站收录的节目无意侵犯了贵司版权,请发邮件(我们会在3个工作日内删除侵权内容,谢谢。)
www.fs94.org-飞速影视 粤ICP备74369512号